Are we approaching “Google zero”, where Google searches will use generative AI systems to summarize responses to queries, thus ending the reason for people to visit website? And if that happens what is lost?
These are common questions that have been building month over month as more advanced foundational models are built, deployed, and iterated upon. But there has been relatively little assessment in public forums around the social dimensions of making a web search. Instead, the focus has tended to be on loss of traffic and subsequent economic effects of this transition.
A 2022 paper entitled “Situating Search” identifies what a search engine does, and what it is used for, in order for the authors to argue that search that only provides specific requested information (often inaccurately) fails to account for the broader range of things that people use search for.
Specifically, when people search they:
lookup
learn
investigate
When a ChatGPT or Gemini approach to search is applied, however, it limits the range of options before a user. Specifically, in binding search to conversational responses we may impair individuals from conducting search/learning in ways that expand domain knowledge or that rely on sensemaking of results to come to a given conclusion.
Page 227 of the paper has a helpful overview of the dimensions of Information Seeking Strategies (ISS), which explain the links between search and the kinds of activities in which individuals engage. Why, also, might chat-based (or other multimodal) search be a problem?
it can come across as too authoritative
by synthesizing data from multiple sources and masking the available range of sources, it cuts the individual’s ability to expose the broader knowledge space
LLMs, in synthesizing text, may provide results that are not true
All of the above issues are compounded in situations where individuals have low information literacy and, thus, are challenged in their ability to recognize deficient responses from an AI-based search system.
The authors ultimately conclude with the following:
…we should be looking to build tools that help users find and make sense of information rather than tools that purport to do it all for them. We should also acknowledge that the search systems are used and will continue to be used for tasks other than simply finding an answer to a question; that there is tremendous value in information seekers exploring, stumbling, and learning through the process of querying and discovery through these systems.
As we race to upend the systems we use, today, we should avoid moving quickly and breaking things and instead opt to enhance and improve our knowledge ecosystem. There is a place for these emerging technologies but rather than bolting them onto–and into–all of our information technologies we should determine when they are or are not fit for a given purpose.
A good article by The Markup assessed the accuracy of New York City’s municipal chatbot. The chatbot is intended to provide New Yorkers with information about starting or operating a business in the city. The journalists found the chatbot regularly provided false or incorrect information which could result in legal repercussions for businesses and significantly discriminate against city residents. Problematic outputs included incorrect housing-related information, whether businesses must accept cash for services rendered, whether employers can take cuts of employees’ tips, and more.
While New York does include a warning to those using the chatbot, it remains unclear (and perhaps doubtful) that residents who use it will know when to dispute outputs. Moreover, the statements of how the tool can be helpful and sources it is trained on may cause individuals to trust the chatbot.
In aggregate, this speaks to how important it is to effectively communicate with users, in excess of policies simply mandating some kind of disclosure of the risks associated with these tools, as well as demonstrates the importance of government institutions more carefully assessing (and appreciating) the risks of these systems prior to deploying them.
In January, the UK’s National Cyber Security Centre (NCSC) published its assessment of the near-term impact of AI with regards to cyber threats. The whole assessment is worth reading for its clarity and brevity in identifying different ways that AI technologies will be used by high-capacity state actors, by other state and well resourced criminal and mercenary actors, and by comparatively low-skill actors.
A few items which caught my eye:
More sophisticated uses of AI in cyber operations are highly likely to be restricted to threat actors with access to quality training data, significant expertise (in both AI and cyber), and resources. More advanced uses are unlikely to be realised before 2025.
AI will almost certainly make cyber operations more impactful because threat actors will be able to analyse exfiltrated data faster and more effectively, and use it to train AI models.
AI lowers the barrier for novice cyber criminals, hackers-for-hire and hacktivists to carry out effective access and information gathering operations. This enhanced access will likely contribute to the global ransomware threat over the next two years.
Cyber resilience challenges will become more acute as the technology develops. To 2025, GenAI and large language models will make it difficult for everyone, regardless of their level of cyber security understanding, to assess whether an email or password reset request is genuine, or to identify phishing, spoofing or social engineering attempts.
There are more insights, such as the value of training data held by high capacity actors and the likelihood that low skill actors will see significant upskilling over the next 18 months due to the availability of AI technologies.
The potential to assess information more quickly may have particularly notable impacts in the national security space, enable more effective corporate espionage operations, as well as enhance cyber criminal activities. In all cases, the ability to assess and query volumes of information at speed and scale will let threat actors extract value from information more efficiently than today.
The fact that the same technologies may enable lower-skilled actors to undertake wider ransomware operations, where it will be challenging to distinguish legitimate versus illegitimate security-related emails, also speaks to the desperate need for organizations to transition to higher-security solutions, including multiple factor authentication or passkeys.
In January, the UK’s National Cyber Security Centre (NCSC) published its assessment of the near-term impact of AI with regards to cyber threats. The whole assessment is worth reading for its clarity and brevity in identifying different ways that AI technologies will be used by high-capacity state actors, by other state and well resourced criminal and mercenary actors, and by comparatively low-skill actors.
A few items which caught my eye:
More sophisticated uses of AI in cyber operations are highly likely to be restricted to threat actors with access to quality training data, significant expertise (in both AI and cyber), and resources. More advanced uses are unlikely to be realised before 2025.
AI will almost certainly make cyber operations more impactful because threat actors will be able to analyse exfiltrated data faster and more effectively, and use it to train AI models.
AI lowers the barrier for novice cyber criminals, hackers-for-hire and hacktivists to carry out effective access and information gathering operations. This enhanced access will likely contribute to the global ransomware threat over the next two years.
Cyber resilience challenges will become more acute as the technology develops. To 2025, GenAI and large language models will make it difficult for everyone, regardless of their level of cyber security understanding, to assess whether an email or password reset request is genuine, or to identify phishing, spoofing or social engineering attempts.
There are more insights, such as the value of training data held by high capacity actors and the likelihood that low skill actors will see significant upskilling over the next 18 months due to the availability of AI technologies.
The potential to assess information more quickly may have particularly notable impacts in the national security space, enable more effective corporate espionage operations, as well as enhance cyber criminal activities. In all cases, the ability to assess and query volumes of information at speed and scale will let threat actors extract value from information more efficiently than today.
The fact that the same technologies may enable lower-skilled actors to undertake wider ransomware operations, where it will be challenging to distinguish legitimate versus illegitimate security-related emails, also speaks to the desperate need for organizations to transition to higher-security solutions, including multiple factor authentication or passkeys.
A whole computing infrastructure based on tracking metadata reliably and then presenting it to users in ways they understand and care about, and which is adopted by the masses.
That generative outputs will need to remain the exception as opposed to the norm: when generative image manipulation (not full image creation) is normal then how much will this glyph help to notify people of ‘fake’ imagery or other content?
That there are sufficiently low benefits to offering metadata-stripping or content-modification or content-creation systems that there are no widespread or easy-to-adopt ways of removing the identifying metadata from generative content.
Finally, where the intent behind fraudulent media is to intimidate, embarrass, or harass (e.g., non-consensual deepfake pornographic content, violence content), then what will the glyph in question do to allay these harms? I suspect very little unless it is, also, used to identify individuals who create content for the purposes of addressing criminal or civil offences. And, if that’s the case, then the outputs would constitute a form of data that are designed to deliberately enable state intervention in private life, which could raise a series of separate, unique, and difficult to address problems.
I’m a street photographer and have taken tens of thousands of images over the past decade. For the past couple years I’ve moved my photo sharing over to Glass, a member-paid social network that beautifully represents photographers’ images and provides a robust community to share and discuss the images that are posted.
I’m a big fan of Glass and have paid for it repeatedly. I currently expect to continue doing so. But while I’ve been happy with all their new features and updates previously, the newly announced computer vision-enabled search is a failure at launch and should be pulled from public release.
To be clear: I think that this failure can (and should) be rectified and this post documents some of the present issues with Glass’ AI-enabled search so their development team can subsequently work to further improve search and discoverability on the platform. The post is not intended to tarnish or otherwise belittle Glass’s developers or their hard work to build a safe and friendly photo sharing platform and community.
Trust and Safety and AI technologies
It’s helpful to start with a baseline recognition that computer vision technologies tend to be, at their core, anti-human. A recent study of academic papers and patents revealed how computer vision research fundamentally strips individuals of their humanity by way of referring to them as objects. This means that any technology which adopts computer vision needs to do so in a thoughtful and careful way if it is to avoid objectifying humans in harmful ways.
But beyond that, there are key trust and safety issues that are linked to AI models which are relied upon to make sense of otherwise messy data. In the case of photographs, a model can be used to subsequently enable queries against the photos, such as by classifying men or women in images, or classifying different kinds of scenes or places, or so as to surface people who hold different kinds of jobs. At issue, however, is thatmanyofthe popular AI models have deep or latent biases — queries for ‘doctors’ surface men, ‘nurses’ women, ‘kitchens’ associated with images including women, ‘worker’ surfacing men — or they fundamentally fail to correctly categorize what is in the image, with the result of surfacing images that are not correlated with the search query. This latter situation becomes problematic when the errors are not self-evident to the viewer, such as when searching for one location (e.g., ‘Toronto’) reveals images of different places (e.g., Chicago, Singapore, or Melbourne) but that a viewer may not be able to detect as erroneous.
Bias is a well known issue amongst anyone developing or implementing AI systems. There are numerous ways to try to technically address bias as well as policy levers that ought to be relied upon when building out an AI system. As just one example, when training a model it is best practice to include a dataset card, which explains the biases or other characteristics of the dataset in question. These dataset cards can also explain to future users or administrators how the AI system was developed so future administrators can better understand the history behind past development efforts. To some extent, you can think of dataset cards as a policy appendix to a machine language model, or as the ‘methods’ and ‘data’ section of a scientific paper.
Glass, Computer Vision, and Ethics
One of Glass’ key challenges since its inception has been around onboarding and enabling users to find other, relevant, photographers or images. While the company has improved things significantly over the past year there was still a lot of manual work to find relevant work, and to find photographers who are active on the platform. It was frustrating for everyone and especially to new users, or when people who posted photos didn’t categorize their images with the effect of basically making them undiscoverable.
One way to ‘solve’ this has been to apply a computer vision model that is designed to identify common aspects of photos — functionally label them with descriptions — and then let Glass users search against these aspects or labels. The intent is positive and, if done well, could overcome a major issue in searching imagery both because the developers can build out a common tagging system and because most people won’t take the time to provide detailed tags for their images were the option provided to them.
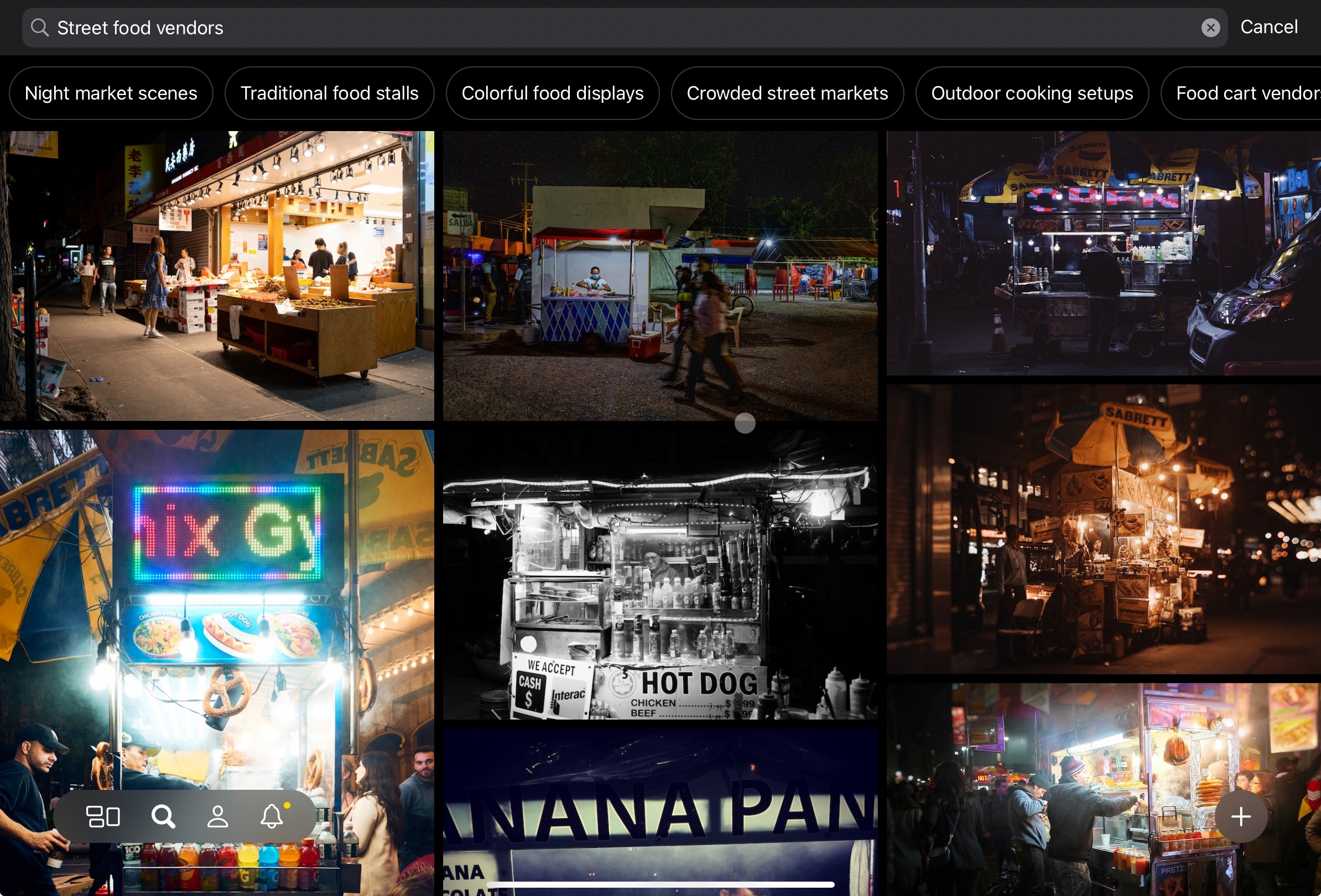
Sometimes the system seems to work pretty well. Searching for ‘street food vendors’ pulls up pretty accurate results.
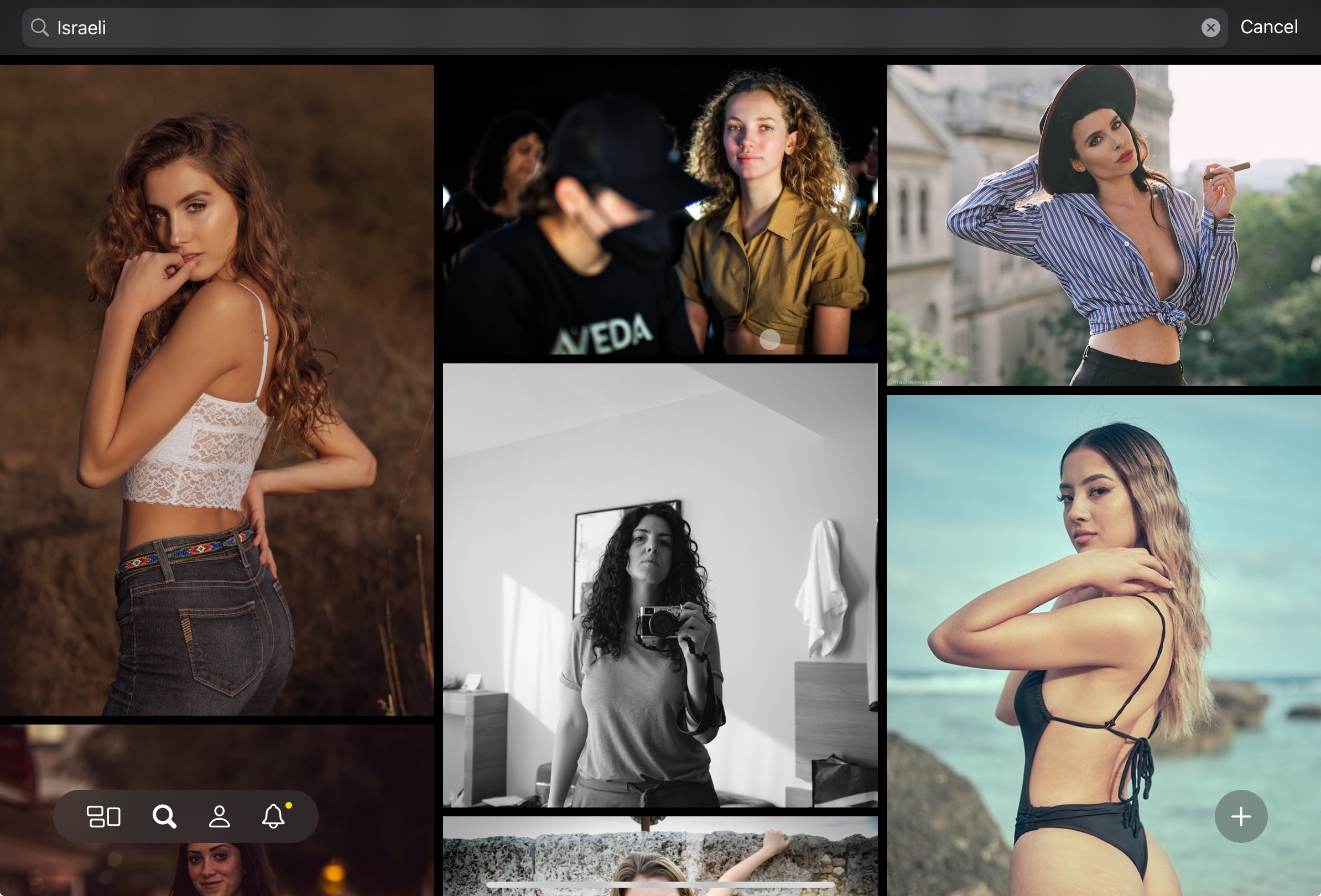
However, when I search for ‘Israeli’ I’m served with images of women. When I open them up there is no information suggesting that the women are, in fact, Israeli, and in some cases images are shot outside of Israel. Perhaps the photographers are Israeli? Or there is location-based metadata that geolocates the images to Israel? Regardless, it seems suspicious that this term almost exclusively surfaces women.
Searching ‘Arab’ also brings up images of women, including some who are in headscarves. It is not clear that each of the women are Arabic. Moreover, it is only after 8 images of women are presented is a man in a beard shown. This subject, however, does not have any public metadata that indicates he is, or identifies as being, Arabic.
Similar gender-biased results happen when you search for ‘Brazillian’, ‘Russian’, ‘Mexican’, or ‘African’. When you search for ‘European’, ‘Canadian’, ‘American’, ‘Japanese’, however, you surface landscapes and streetscapes in addition to women.
Other searches produce false results. This likely occurs because the AI model has been trained that certain items in scenes are correlated to concepts. As an example, when you search for ‘nurse’ the results are often erroneous (e.g., this photo by L E Z) or link a woman in a face mask to being a nurse. There are, of course, also just sexualized images of women.
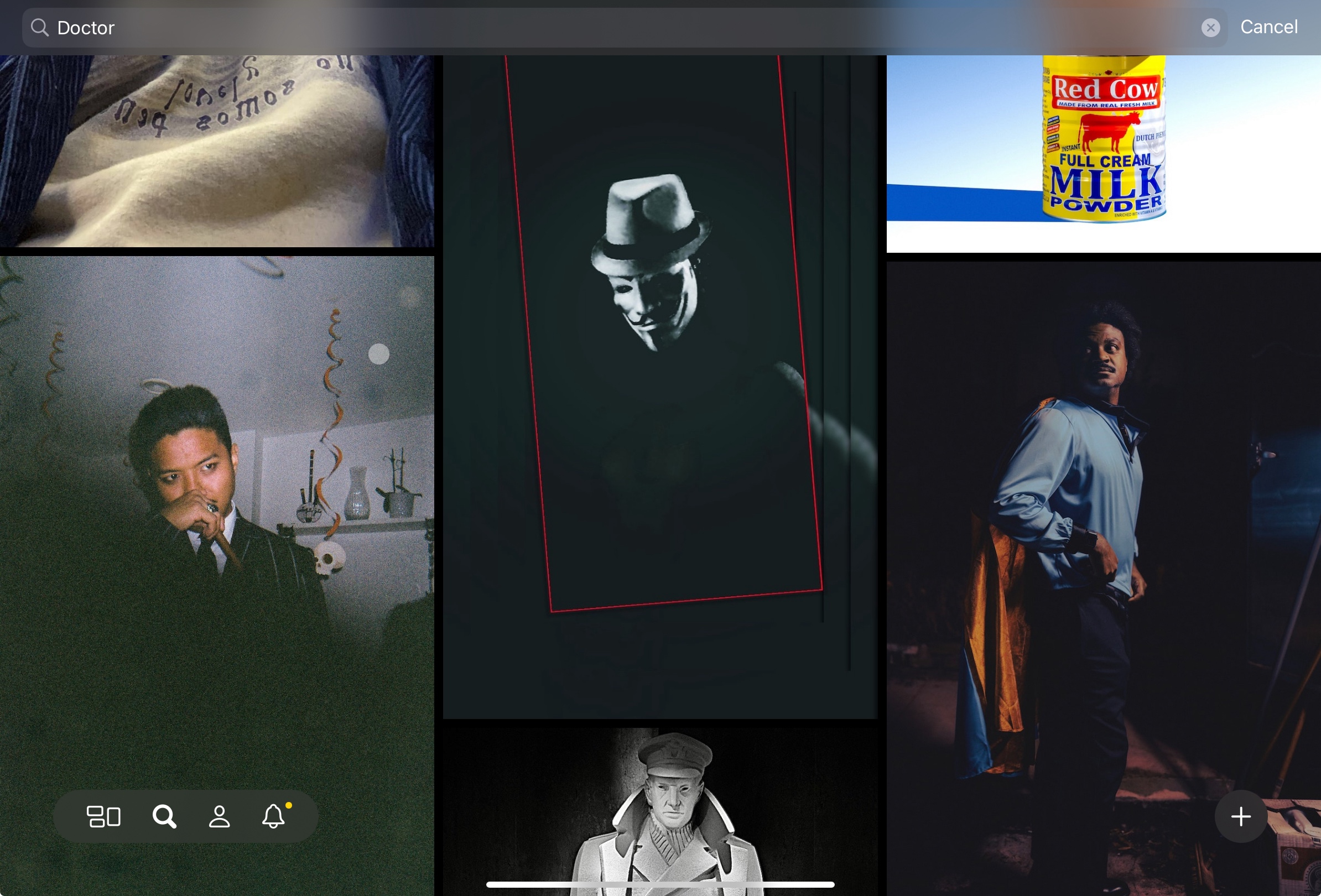
When searching for ‘doctor’ we can see that the model likely has some correlation between a mask and being a doctor but, aside from that, the images tend to return male subjects as images. Unlike ‘nurse’ there are no sexualized images of men or women that immediately are surfaced.
Also, if you do a search for ‘hot’ you are served — again — with images of sexualized women. While the images tend to be ‘warm’ colours they do not include streetscapes or landscapes.
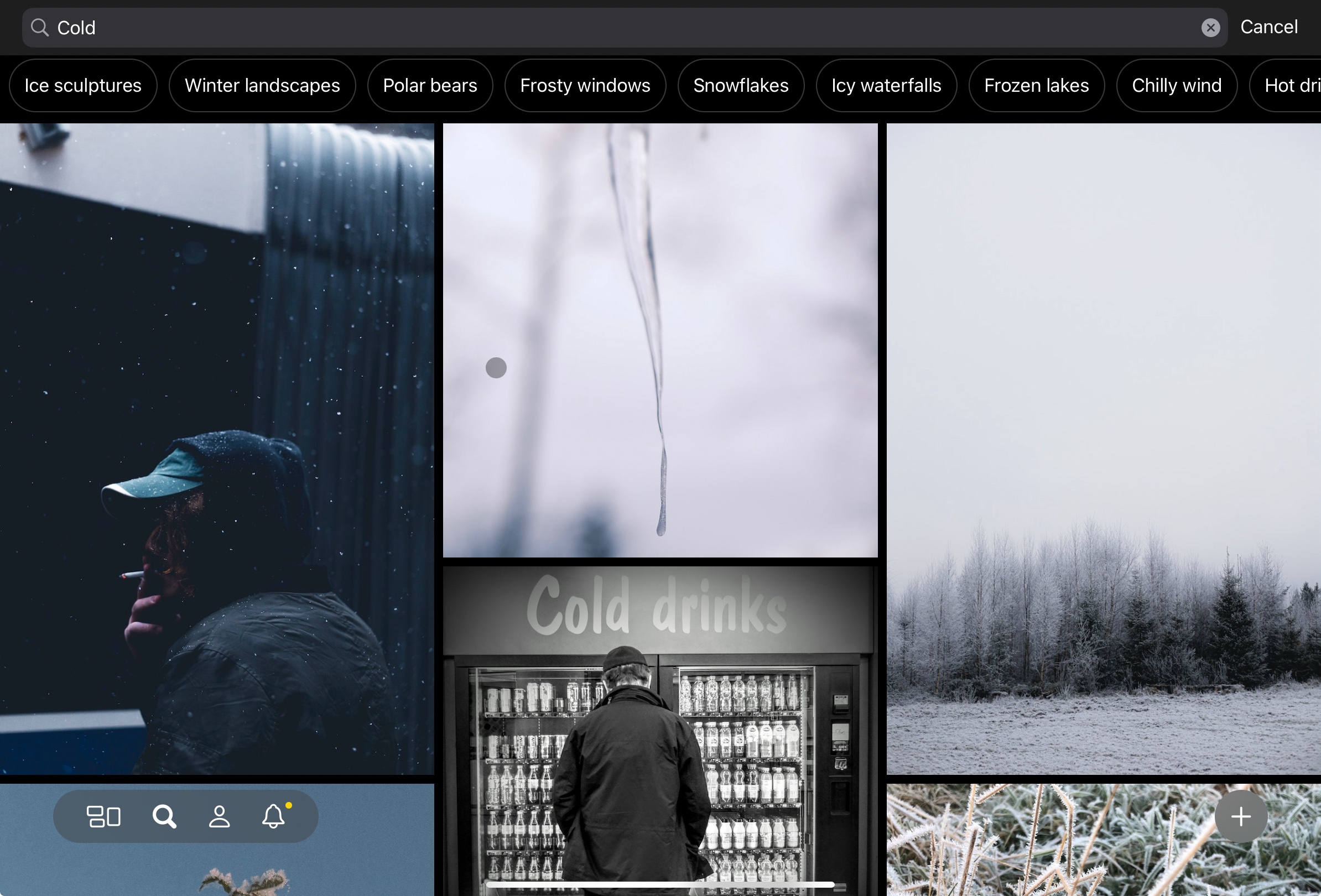
Doing a search for ‘cold’, however, and you get cold colours (i.e., blues) along with images of winter scenes. Sexualized female images are not presented.
Consider also some of the search queries which are authorized and how they return results:
‘slut’ which purely surfaces women
‘tasty’ which surfaces food images along with images of women
‘lover’ which surfaces images of men and women, or women alone. It is rare that men are shown on their own
‘juicy’ which tends to return images of fruit or of sexualized women
‘ugly’ which predominantly surfaces images of men
‘asian’ which predominantly returns images of sexualized Asian women
‘criminal’ which often appears linked to darker skin or wearing a mask
‘jew’ which (unlike Israeli) exclusively surfaces men for the first several pages of returned images
‘black’ primarily surfaces women in leather or rubber clothing
‘white’ principally surfaces white women or women in white clothing
Note that I refrained from any particularly offensive queries on the basis that I wanted to avoid taking any actions that could step over an ethical or legal line. I also did not attempt to issue any search queries using a language other than English. All queries were run on October 15, 2023 using my personal account with the platform.
Steps Forward
There are certainly images of women who have been published on Glass and this blogpost should not be taken as suggesting that these images should be removed. However, even running somewhat basic queries reveal that (at a minimum) there is an apparent gender bias in how some tags are associated with men or women. I have only undertaken the most surface level of queries and have not automated searches or loaded known ‘problem words’ to query against Glass. I also didn’t have to.
Glass’ development team should commit to pulling its computer vision/AI-based search back into a beta or to pull the system entirely. Either way, what the developers have pushed into production is far from ready for prime time if the company—and the platform and its developers—are to be seen as promoting an inclusive and equitable platform that avoids reaffirming historical biases that are regularly engrained in poorly managed computer vision technologies.
Glass’ developers have previously shown that they deeply care about getting product developments right and about fostering a safe and equitable platform. It’s one of the reasons that they are building a strong and healthy community on the platform. As it stands today, however, their AI-powered search function violates these admirable company values.
I hope that the team corrects this error and brings the platform, and its functions, back into comportment with the company’s values rather than continue to have a clearly deficient product feature deployed for all users. Maintaining the search features, as it exists today, would undermine the team’s efforts to otherwise foster the best photographic community available on the Internet, today.
Glass’ developers have shown attentiveness to the community in developing new features and fixing bugs, and I hope that they read this post as one from a dedicated and committed user who just wants the platform to be better. I like Glass and the developers’ values, and hope these values are used to undergird future explore and search functions as opposed to the gender-biased values that are currently embedded in Glass’ AI-empowered search functions.
Rolling Stone has an excellent article that profiles the women who have been at the forefront of warning how contemporary AI systems can be, and are being, used to (re)inscribe bias, discrimination, sexism, and racism into contemporary and emerging digital tools and systems. An important read that is well worth your time.
This article by Ramani and Wang, entitled “Why transformative AI is really, really hard to achieve,” is probably the best critical economic analysis of the current AI debates I’ve come across. It assesses what would be required for AI technologies to live up to the current hype cycles about how these technologies will massively benefit economic productivity. Based on the nature of AI technologies being developed, combined with the history of economic productivity enhancements over time, the authors conclude that the present day hype is unlikely to be met.
Key to the arguments is that AI technologies do not, as of yet, sufficiently automate a vast set of tasks which are comparatively easy for humans to accomplish, nor are they able to benefit from the latent knowledge and intelligence that guides humans in their daily lives. The authors argue that AI technologies must broadly automate tasks, instead of discretely automating them, in order to achieve cross-industry improvements to productivity. Doing otherwise will merely accelerate aspects of processes which will remain gridlocked in the aggregate by more traditional or less automated processes.
The authors are not dismissing the potential utility of AI technologies, however, but instead just arguing that they are not as likely to achieve the transformative economic miracles that many are suggesting are just around the corner. However, even if AI systems are ‘only’ as significant for productivity as the combustion engine (which discretely as opposed to comprehensively enhanced productivity) this would be a significant accomplishment.
I found boyd’s “Deskilling on the Job” to be a useful framing for how to be broadly concerned, or at least thoughtful, about using emerging A.I. technologies in professional as well as training environments.
Most technologies serve to augment human activity. In sensitive situations we often already require a human-in-the-loop to respond to dangerous errors (see: dam operators, nuclear power staff, etc). However, should emerging A.I. systems’ risks be mitigated by also placing humans-in-the-loop then it behooves policymakers to ask: how well does this actually work when we thrust humans into correcting often highly complicated issues moments before a disaster?
Not to spoil things, but it often goes poorly, and we then blame the humans in the loop instead of the technical design of the system.1
AI technologies offer an amazing bevy of possibilities. But thinking more carefully on how to integrate them into society while, also, digging into history and scholarly writing in automation will almost certainly help us avoid obvious, if recurring, errors in how policy makers think about adding guardrails around AI systems.
If this idea of humans-in-the-loop and the regularity of errors in automated systems interests you, I’d highly encourage you to get a copy of ‘Normal Accidents’ by Perrow. ↩︎
Government agencies throughout Canada are investigating how they might adopt and deploy ‘artificial intelligence’ programs to enhance how they provide services. In the case of national security and law enforcement agencies these programs might be used to analyze and exploit datasets, surface threats, identify risky travellers, or automatically respond to criminal or threat activities.
However, the predictive software systems that are being deployed–‘artificial intelligence’–are routinely shown to be biased. These biases are serious in the commercial sphere but there, at least, it is somewhat possible for researchers to detect and surface biases. In the secretive domain of national security, however, the likelihood of bias in agencies’ software being detected or surfaced by non-government parties is considerably lower.
I know that organizations such as the Canadian Security Intelligence Agency (CSIS) have an interest in understanding how to use big data in ways that mitigate bias. The Canadian government does have a policy on the “Responsible use of artificial intelligence (AI)” and, at the municipal policing level, the Toronto Police Service has also published a policy on its use of artificial intelligence. Furthermore, the Office of the Privacy Commissioner of Canada has published a proposed regulatory framework for AI as part of potential reforms to federal privacy law.
Timnit Gebru, in conversation with Julia Angwin, suggests that there should be ‘datasheets for algorithms’ that would outline how predictive software systems have been tested for bias in different use cases prior to being deployed. Linking this to traditional circuit-based datasheets, she says (emphasis added):
As a circuit designer, you design certain components into your system, and these components are really idealized tools that you learn about in school that are always supposed to work perfectly. Of course, that’s not how they work in real life.
To account for this, there are standards that say, “You can use this component for railroads, because of x, y, and z,” and “You cannot use this component for life support systems, because it has all these qualities we’ve tested.” Before you design something into your system, you look at what’s called a datasheet for the component to inform your decision. In the world of AI, there is no information on what testing or auditing you did. You build the model and you just send it out into the world. This paper proposed that datasheets be published alongside datasets. The sheets are intended to help people make an informed decision about whether that dataset would work for a specific use case. There was also a follow-up paper called Model Cards for Model Reporting that I wrote with Meg Mitchell, my former co-lead at Google, which proposed that when you design a model, you need to specify the different tests you’ve conducted and the characteristics it has.
What I’ve realized is that when you’re in an institution, and you’re recommending that instead of hiring one person, you need five people to create the model card and the datasheet, and instead of putting out a product in a month, you should actually do it in three years, it’s not going to happen. I can write all the papers I want, but it’s just not going to happen. I’m constantly grappling with the incentive structure of this industry. We can write all the papers we want, but if we don’t change the incentives of the tech industry, nothing is going to change. That is why we need regulation.
Government is one of those areas where regulation or law can work well to discipline its behaviours, and where the relatively large volume of resources combined with a law-abiding bureaucracy might mean that formally required assessments would actually be conducted. While such assessments matter, generally, they are of particular importance where state agencies might be involved in making decisions that significantly or permanently alter the life chances of residents of Canada, visitors who are passing through our borders, or foreign national who are interacting with our government agencies.
As it stands, today, many Canadian government efforts at the federal, provincial, or municipal level seem to be signficiantly focused on how predictive software might be used or the effects it may have. These are important things to attend to! But it is just as, if not more, important for agencies to undertake baseline assessments of how and when different predictive software engines are permissible or not, as based on robust testing and evaluation of their features and flaws.
Having spoken with people at different levels of government the recurring complaint around assessing training data, and predictive software systems more generally, is that it’s hard to hire the right people for these assessment jobs on the basis that they are relatively rare and often exceedingly expensive. Thus, mid-level and senior members of government have a tendency to focus on things that government is perceived as actually able to do: figure out and track how predictive systems would be used and to what effect.
However, the regular focus on the resource-related challenges of predictive software assessment raises the very real question of whether these constraints should just compel agencies to forgo technologies on the basis of failing to determine, and assess, their prospective harms. In the firearms space, as an example, government agencies are extremely rigorous in assessing how a weapon operates to ensure that it functions precisely as meant given that the weapon might be used in life-changing scenarios. Such assessments require significant sums of money from agency budgets.
If we can make significant budgetary allocations for firearms, on the grounds they can have life-altering consequences for all involved in their use, then why can’t we do the same for predictive software systems? If anything, such allocations would compel agencies to make a strong(er) business case for testing the predictive systems in question and spur further accountability: Does the system work? At a reasonable cost? With acceptable outcomes?
Imposing cost discipline on organizations is an important way of ensuring that technologies, and other business processes, aren’t randomly adopted on the basis of externalizing their full costs. By internalizing those costs, up front, organizations may need to be much more careful in what they choose to adopt, when, and for what purpose. The outcome of this introspection and assessment would, hopefully, be that the harmful effects of predictive software systems in the national security space were mitigated and the systems which were adopted actually fulfilled the purposes they were acquired to address.