Nilay Patel recently interviewed Bridget McCormack, former chief justice of the Michigan Supreme Court and now head of the American Arbitration Association (AAA), about the AAA’s new AI-assisted arbitration platform and the broader role AI might play in legal dispute resolution. It was a rich conversation, touching on the design and mechanics of the AI arbitration system, procedural fairness and perceived trust, and the limits and risks and opportunities of deploying AI in adjudicative contexts.
McCormack raised a number of ways that agentic AI systems can be used in arbitration processes, including:
case intake and understanding parties’ positions,
organizing some evidence supplied by parties,
providing mechanisms for parties to assess whether they even want to bring a case to arbitration,
establishing less-biased (or more bias evident) decision systems that lend themselves to auditing, and
more broadly expanding access to arbitration processes by reducing costs and time linked with these activities.
The AAA has worked slowly and carefully in developing their AI-enabled processes, and it will be interesting to see the outcomes of their innovations. Similarly, I’ll be curious to see whether (and if so, how) other adjudication and tribunal bodies look to adopt these technologies in the coming months and years.
A new study from the London School of Economics highlights how AI systems can reinforce existing inequalities when used for high risk activities like social care.
Writing in The Guardian, Jessica Murray describes how Google’s Gemma model summarized identical case notes differently depending on gender.
An 84-year-old man, “Mr Smith,” was described as having a “complex medical history, no care package and poor mobility,” while “Mrs Smith” was portrayed as “[d]espite her limitations, she is independent and able to maintain her personal care.” In another example, Mr Smith was noted as “unable to access the community,” but Mrs Smith as “able to manage her daily activities.”
These subtle but significant differences risk making women’s needs appear less urgent, and could influence the care and resources provided. By contrast, Meta’s Llama 3 did not use different language based on gender, underscoring that bias can vary across models and the need to measure bias in LLMs adopted for public service delivery
These findings reinforce why AI systems must be valid and reliable, safe, transparent, accountable, privacy-protective, and human-rights affirming. This is especially the case in high risk settings where AI systems affect decisions linked with accessing essential public services.
I’m a street photographer and have taken tens of thousands of images over the past decade. For the past couple years I’ve moved my photo sharing over to Glass, a member-paid social network that beautifully represents photographers’ images and provides a robust community to share and discuss the images that are posted.
I’m a big fan of Glass and have paid for it repeatedly. I currently expect to continue doing so. But while I’ve been happy with all their new features and updates previously, the newly announced computer vision-enabled search is a failure at launch and should be pulled from public release.
To be clear: I think that this failure can (and should) be rectified and this post documents some of the present issues with Glass’ AI-enabled search so their development team can subsequently work to further improve search and discoverability on the platform. The post is not intended to tarnish or otherwise belittle Glass’s developers or their hard work to build a safe and friendly photo sharing platform and community.
Trust and Safety and AI technologies
It’s helpful to start with a baseline recognition that computer vision technologies tend to be, at their core, anti-human. A recent study of academic papers and patents revealed how computer vision research fundamentally strips individuals of their humanity by way of referring to them as objects. This means that any technology which adopts computer vision needs to do so in a thoughtful and careful way if it is to avoid objectifying humans in harmful ways.
But beyond that, there are key trust and safety issues that are linked to AI models which are relied upon to make sense of otherwise messy data. In the case of photographs, a model can be used to subsequently enable queries against the photos, such as by classifying men or women in images, or classifying different kinds of scenes or places, or so as to surface people who hold different kinds of jobs. At issue, however, is thatmanyofthe popular AI models have deep or latent biases — queries for ‘doctors’ surface men, ‘nurses’ women, ‘kitchens’ associated with images including women, ‘worker’ surfacing men — or they fundamentally fail to correctly categorize what is in the image, with the result of surfacing images that are not correlated with the search query. This latter situation becomes problematic when the errors are not self-evident to the viewer, such as when searching for one location (e.g., ‘Toronto’) reveals images of different places (e.g., Chicago, Singapore, or Melbourne) but that a viewer may not be able to detect as erroneous.
Bias is a well known issue amongst anyone developing or implementing AI systems. There are numerous ways to try to technically address bias as well as policy levers that ought to be relied upon when building out an AI system. As just one example, when training a model it is best practice to include a dataset card, which explains the biases or other characteristics of the dataset in question. These dataset cards can also explain to future users or administrators how the AI system was developed so future administrators can better understand the history behind past development efforts. To some extent, you can think of dataset cards as a policy appendix to a machine language model, or as the ‘methods’ and ‘data’ section of a scientific paper.
Glass, Computer Vision, and Ethics
One of Glass’ key challenges since its inception has been around onboarding and enabling users to find other, relevant, photographers or images. While the company has improved things significantly over the past year there was still a lot of manual work to find relevant work, and to find photographers who are active on the platform. It was frustrating for everyone and especially to new users, or when people who posted photos didn’t categorize their images with the effect of basically making them undiscoverable.
One way to ‘solve’ this has been to apply a computer vision model that is designed to identify common aspects of photos — functionally label them with descriptions — and then let Glass users search against these aspects or labels. The intent is positive and, if done well, could overcome a major issue in searching imagery both because the developers can build out a common tagging system and because most people won’t take the time to provide detailed tags for their images were the option provided to them.
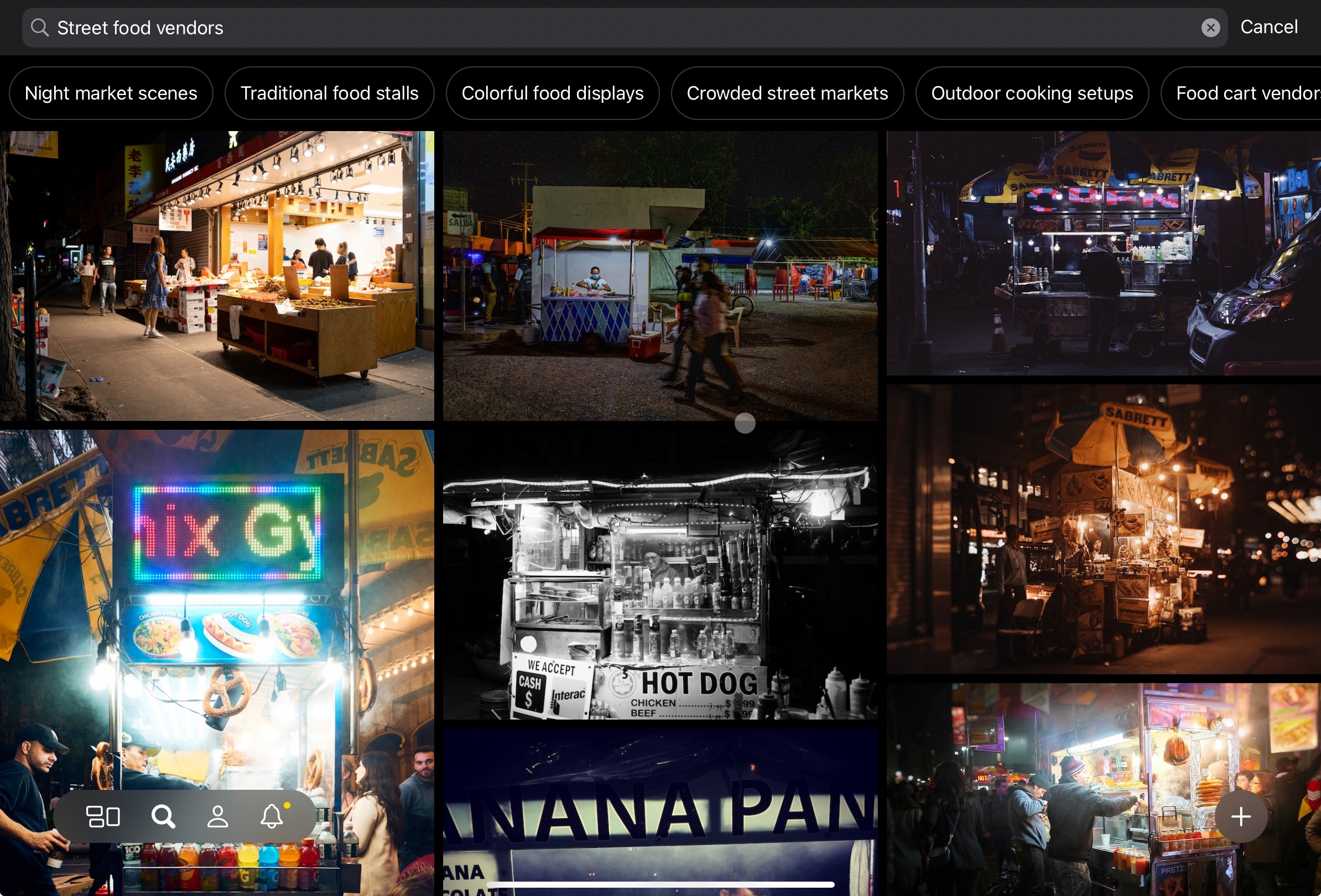
Sometimes the system seems to work pretty well. Searching for ‘street food vendors’ pulls up pretty accurate results.
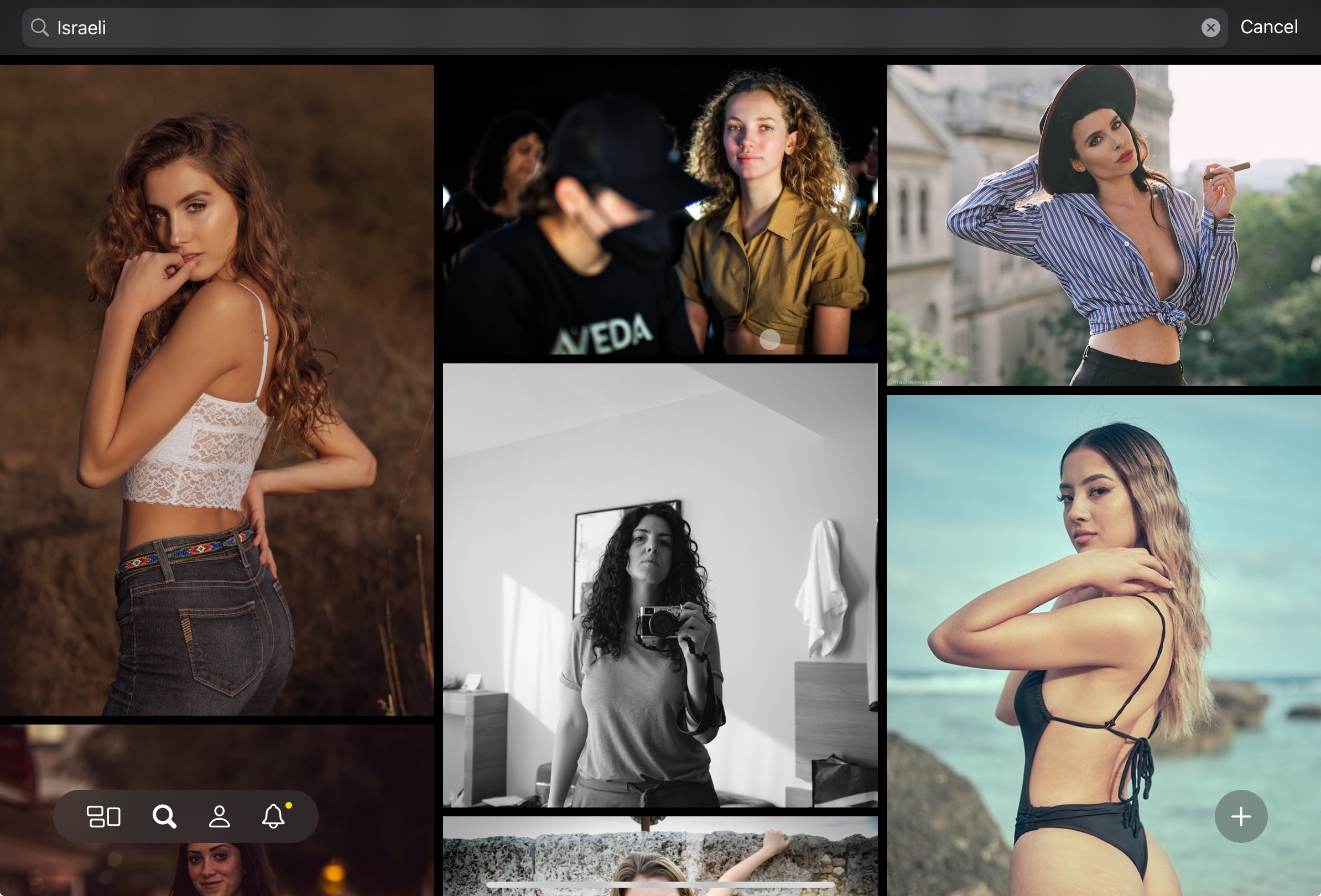
However, when I search for ‘Israeli’ I’m served with images of women. When I open them up there is no information suggesting that the women are, in fact, Israeli, and in some cases images are shot outside of Israel. Perhaps the photographers are Israeli? Or there is location-based metadata that geolocates the images to Israel? Regardless, it seems suspicious that this term almost exclusively surfaces women.
Searching ‘Arab’ also brings up images of women, including some who are in headscarves. It is not clear that each of the women are Arabic. Moreover, it is only after 8 images of women are presented is a man in a beard shown. This subject, however, does not have any public metadata that indicates he is, or identifies as being, Arabic.
Similar gender-biased results happen when you search for ‘Brazillian’, ‘Russian’, ‘Mexican’, or ‘African’. When you search for ‘European’, ‘Canadian’, ‘American’, ‘Japanese’, however, you surface landscapes and streetscapes in addition to women.
Other searches produce false results. This likely occurs because the AI model has been trained that certain items in scenes are correlated to concepts. As an example, when you search for ‘nurse’ the results are often erroneous (e.g., this photo by L E Z) or link a woman in a face mask to being a nurse. There are, of course, also just sexualized images of women.
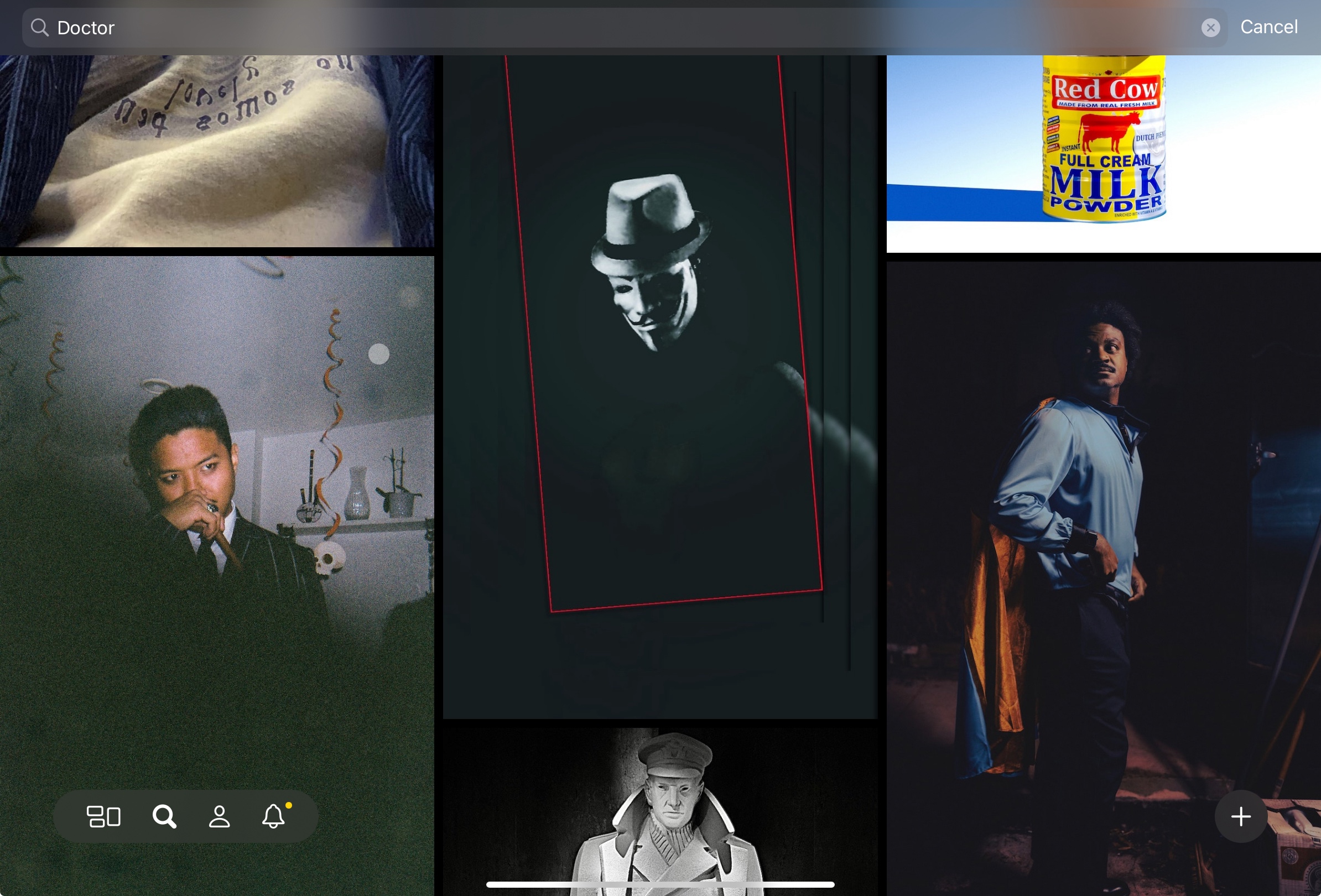
When searching for ‘doctor’ we can see that the model likely has some correlation between a mask and being a doctor but, aside from that, the images tend to return male subjects as images. Unlike ‘nurse’ there are no sexualized images of men or women that immediately are surfaced.
Also, if you do a search for ‘hot’ you are served — again — with images of sexualized women. While the images tend to be ‘warm’ colours they do not include streetscapes or landscapes.
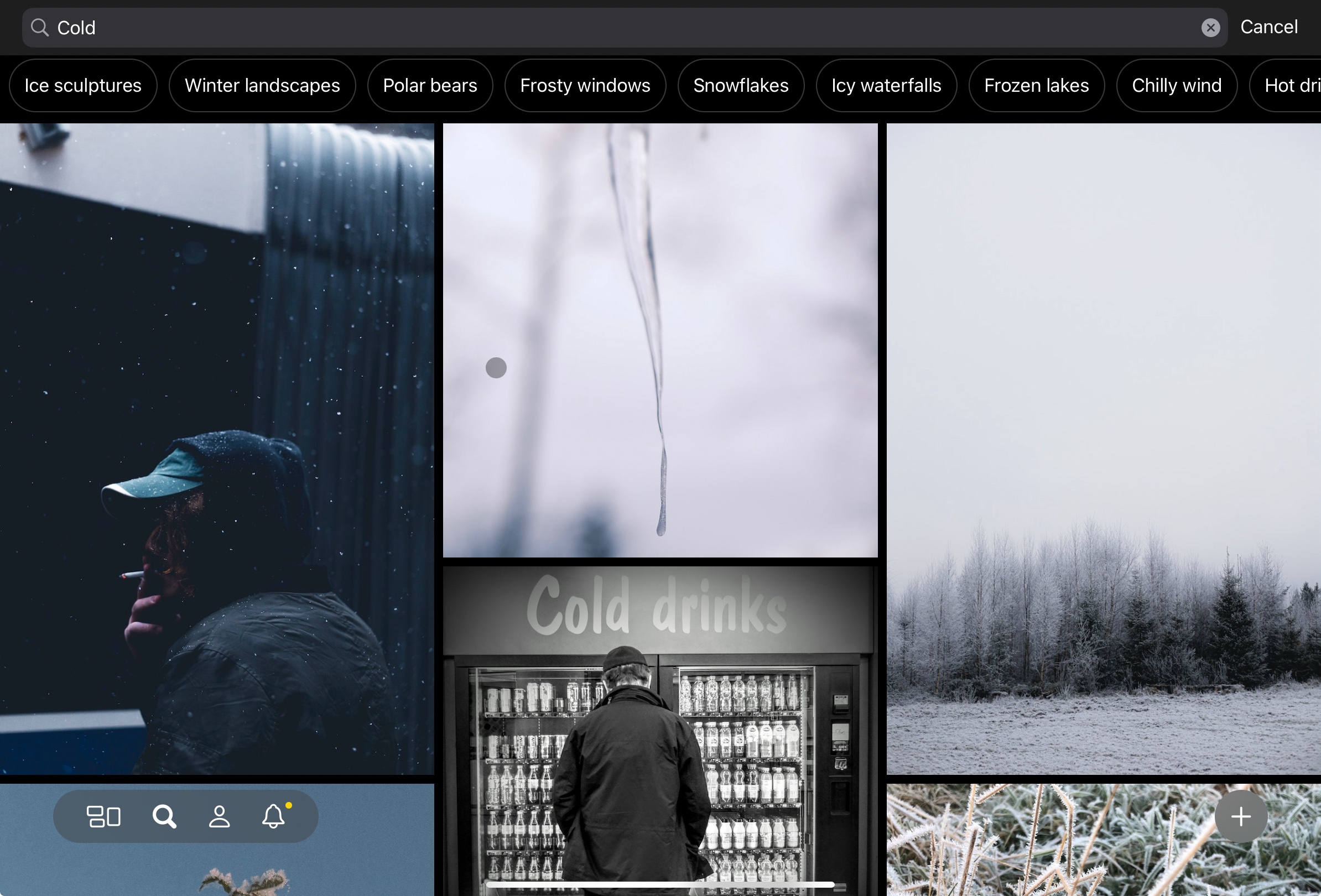
Doing a search for ‘cold’, however, and you get cold colours (i.e., blues) along with images of winter scenes. Sexualized female images are not presented.
Consider also some of the search queries which are authorized and how they return results:
‘slut’ which purely surfaces women
‘tasty’ which surfaces food images along with images of women
‘lover’ which surfaces images of men and women, or women alone. It is rare that men are shown on their own
‘juicy’ which tends to return images of fruit or of sexualized women
‘ugly’ which predominantly surfaces images of men
‘asian’ which predominantly returns images of sexualized Asian women
‘criminal’ which often appears linked to darker skin or wearing a mask
‘jew’ which (unlike Israeli) exclusively surfaces men for the first several pages of returned images
‘black’ primarily surfaces women in leather or rubber clothing
‘white’ principally surfaces white women or women in white clothing
Note that I refrained from any particularly offensive queries on the basis that I wanted to avoid taking any actions that could step over an ethical or legal line. I also did not attempt to issue any search queries using a language other than English. All queries were run on October 15, 2023 using my personal account with the platform.
Steps Forward
There are certainly images of women who have been published on Glass and this blogpost should not be taken as suggesting that these images should be removed. However, even running somewhat basic queries reveal that (at a minimum) there is an apparent gender bias in how some tags are associated with men or women. I have only undertaken the most surface level of queries and have not automated searches or loaded known ‘problem words’ to query against Glass. I also didn’t have to.
Glass’ development team should commit to pulling its computer vision/AI-based search back into a beta or to pull the system entirely. Either way, what the developers have pushed into production is far from ready for prime time if the company—and the platform and its developers—are to be seen as promoting an inclusive and equitable platform that avoids reaffirming historical biases that are regularly engrained in poorly managed computer vision technologies.
Glass’ developers have previously shown that they deeply care about getting product developments right and about fostering a safe and equitable platform. It’s one of the reasons that they are building a strong and healthy community on the platform. As it stands today, however, their AI-powered search function violates these admirable company values.
I hope that the team corrects this error and brings the platform, and its functions, back into comportment with the company’s values rather than continue to have a clearly deficient product feature deployed for all users. Maintaining the search features, as it exists today, would undermine the team’s efforts to otherwise foster the best photographic community available on the Internet, today.
Glass’ developers have shown attentiveness to the community in developing new features and fixing bugs, and I hope that they read this post as one from a dedicated and committed user who just wants the platform to be better. I like Glass and the developers’ values, and hope these values are used to undergird future explore and search functions as opposed to the gender-biased values that are currently embedded in Glass’ AI-empowered search functions.
Government agencies throughout Canada are investigating how they might adopt and deploy ‘artificial intelligence’ programs to enhance how they provide services. In the case of national security and law enforcement agencies these programs might be used to analyze and exploit datasets, surface threats, identify risky travellers, or automatically respond to criminal or threat activities.
However, the predictive software systems that are being deployed–‘artificial intelligence’–are routinely shown to be biased. These biases are serious in the commercial sphere but there, at least, it is somewhat possible for researchers to detect and surface biases. In the secretive domain of national security, however, the likelihood of bias in agencies’ software being detected or surfaced by non-government parties is considerably lower.
I know that organizations such as the Canadian Security Intelligence Agency (CSIS) have an interest in understanding how to use big data in ways that mitigate bias. The Canadian government does have a policy on the “Responsible use of artificial intelligence (AI)” and, at the municipal policing level, the Toronto Police Service has also published a policy on its use of artificial intelligence. Furthermore, the Office of the Privacy Commissioner of Canada has published a proposed regulatory framework for AI as part of potential reforms to federal privacy law.
Timnit Gebru, in conversation with Julia Angwin, suggests that there should be ‘datasheets for algorithms’ that would outline how predictive software systems have been tested for bias in different use cases prior to being deployed. Linking this to traditional circuit-based datasheets, she says (emphasis added):
As a circuit designer, you design certain components into your system, and these components are really idealized tools that you learn about in school that are always supposed to work perfectly. Of course, that’s not how they work in real life.
To account for this, there are standards that say, “You can use this component for railroads, because of x, y, and z,” and “You cannot use this component for life support systems, because it has all these qualities we’ve tested.” Before you design something into your system, you look at what’s called a datasheet for the component to inform your decision. In the world of AI, there is no information on what testing or auditing you did. You build the model and you just send it out into the world. This paper proposed that datasheets be published alongside datasets. The sheets are intended to help people make an informed decision about whether that dataset would work for a specific use case. There was also a follow-up paper called Model Cards for Model Reporting that I wrote with Meg Mitchell, my former co-lead at Google, which proposed that when you design a model, you need to specify the different tests you’ve conducted and the characteristics it has.
What I’ve realized is that when you’re in an institution, and you’re recommending that instead of hiring one person, you need five people to create the model card and the datasheet, and instead of putting out a product in a month, you should actually do it in three years, it’s not going to happen. I can write all the papers I want, but it’s just not going to happen. I’m constantly grappling with the incentive structure of this industry. We can write all the papers we want, but if we don’t change the incentives of the tech industry, nothing is going to change. That is why we need regulation.
Government is one of those areas where regulation or law can work well to discipline its behaviours, and where the relatively large volume of resources combined with a law-abiding bureaucracy might mean that formally required assessments would actually be conducted. While such assessments matter, generally, they are of particular importance where state agencies might be involved in making decisions that significantly or permanently alter the life chances of residents of Canada, visitors who are passing through our borders, or foreign national who are interacting with our government agencies.
As it stands, today, many Canadian government efforts at the federal, provincial, or municipal level seem to be signficiantly focused on how predictive software might be used or the effects it may have. These are important things to attend to! But it is just as, if not more, important for agencies to undertake baseline assessments of how and when different predictive software engines are permissible or not, as based on robust testing and evaluation of their features and flaws.
Having spoken with people at different levels of government the recurring complaint around assessing training data, and predictive software systems more generally, is that it’s hard to hire the right people for these assessment jobs on the basis that they are relatively rare and often exceedingly expensive. Thus, mid-level and senior members of government have a tendency to focus on things that government is perceived as actually able to do: figure out and track how predictive systems would be used and to what effect.
However, the regular focus on the resource-related challenges of predictive software assessment raises the very real question of whether these constraints should just compel agencies to forgo technologies on the basis of failing to determine, and assess, their prospective harms. In the firearms space, as an example, government agencies are extremely rigorous in assessing how a weapon operates to ensure that it functions precisely as meant given that the weapon might be used in life-changing scenarios. Such assessments require significant sums of money from agency budgets.
If we can make significant budgetary allocations for firearms, on the grounds they can have life-altering consequences for all involved in their use, then why can’t we do the same for predictive software systems? If anything, such allocations would compel agencies to make a strong(er) business case for testing the predictive systems in question and spur further accountability: Does the system work? At a reasonable cost? With acceptable outcomes?
Imposing cost discipline on organizations is an important way of ensuring that technologies, and other business processes, aren’t randomly adopted on the basis of externalizing their full costs. By internalizing those costs, up front, organizations may need to be much more careful in what they choose to adopt, when, and for what purpose. The outcome of this introspection and assessment would, hopefully, be that the harmful effects of predictive software systems in the national security space were mitigated and the systems which were adopted actually fulfilled the purposes they were acquired to address.
But testing algorithms for fairness is still largely optional at Facebook. None of the teams that work directly on Facebook’s news feed, ad service, or other products are required to do it. Pay incentives are still tied to engagement and growth metrics. And while there are guidelines about which fairness definition to use in any given situation, they aren’t enforced.
…
The Fairness Flow documentation, which the Responsible AI team wrote later, includes a case study on how to use the tool in such a situation. When deciding whether a misinformation model is fair with respect to political ideology, the team wrote, “fairness” does not mean the model should affect conservative and liberal users equally. If conservatives are posting a greater fraction of misinformation, as judged by public consensus, then the model should flag a greater fraction of conservative content. If liberals are posting more misinformation, it should flag their content more often too.
But members of Kaplan’s team followed exactly the opposite approach: they took “fairness” to mean that these models should not affect conservatives more than liberals. When a model did so, they would stop its deployment and demand a change. Once, they blocked a medical-misinformation detector that had noticeably reduced the reach of anti-vaccine campaigns, the former researcher told me. They told the researchers that the model could not be deployed until the team fixed this discrepancy. But that effectively made the model meaningless. “There’s no point, then,” the researcher says. A model modified in that way “would have literally no impact on the actual problem” of misinformation.
…
[Kaplan’s] claims about political bias also weakened a proposal to edit the ranking models for the news feed that Facebook’s data scientists believed would strengthen the platform against the manipulation tactics Russia had used during the 2016 US election.
The whole thing with ethics is that they have to be integrated such that they underlie everything that an organization does; they cannot function as public relations add ons. Sadly at Facebook the only ethic is growth at all costs, the social implications be damned.
When someone or some organization is responsible for causing significant civil unrest, deaths, or genocide then we expect that those who are even partly responsible to be called to account, not just in the public domain but in courts of law and international justice. And when those someones happen to be leading executives for one of the biggest companies in the world the solution isn’t to berate them in Congressional hearings and hear their weak apologies, but to take real action against them and their companies.
When AI sees a man, it thinks “official.” a woman? “smile”| “The AI services generally saw things human reviewers could also see in the photos. But they tended to notice different things about women and men, with women much more likely to be characterized by their appearance. Women lawmakers were often tagged with “girl” and “beauty.” The services had a tendency not to see women at all, failing to detect them more often than they failed to see men.” // Studies like this help to reveal the bias baked deep into the algorithms that are meant to be ‘impartial’, with this impartiality truly constituting a mathwashing of existent biases that are pernicious to 50% of society.
The ungentle joy of spider sex | “Spectacular though all this is, extreme sexual size dimorphism is rare even in spiders. “It’s an aberration,” Kuntner says. Even so, as he and Coddington describe in the Annual Review of Entomology , close examination of the evolutionary history of spiders indicates that eSSD has evolved at least 16 times, and in one major group some lineages have repeatedly lost it and regained it. The phenomenon is so intriguing it’s kept evolutionary biologists busy for decades. How and why did something so weird evolve?” // This is a truly wild, and detailed, discussion of the characteristics of spider evolution and intercourse.